Introduction to Information Retrieval in RAG pipelines


In this article, we’ll pull back the curtain and share the tools, methodologies, and tricks we use to build robust and reliable RAG systems so you can get a firm handle on what is going on under the hood. In the article to follow, we will explain precisely what IR (Information Retrieval) in RAG is, how it works, its various applications; covering keyword search, semantic search, hybrid search, and metadata filtering.
I do think of it as a workforce. This is a workforce that will conduct end-to-end processes, replacing many tasks being performed today by the human workforce. Jorge Amar, McKinsey Senior Partner, June 3 2025, on The future of work is agentic
What is RAG?
RAG, Retrieval Augmented Generation, is an AI-enhancing tool that combines the power of information retrieval and text generation to fetch relevant data from a large database before generating a response. This RAG process helps improve the quality and relevance of generated responses by incorporating specific and citable facts. The RAG approach is particularly useful for chatbots, AI assistants, and other applications that require accurate and contextually relevant information.
RAG allows LLMs to access and reference information outside the LLMs own training data, such as an organization’s specific knowledge base, before generating a response—and, crucially, with citations included. This capability enables LLMs to produce highly specific outputs without extensive fine-tuning or training, delivering some of the benefits of a custom LLM at considerably less expense. Lareina Yee, Senior Partner of McKinsey, October 30, 2024, on What is retrieval-augmented generation (RAG)?
What is IR?
Information Retrieval (IR) is the process of extracting relevant information from various sources. In the context of RAG systems, this typically means retrieving data from a knowledge base – most often a vector database. The component responsible for this in RAG is the retriever. Here’s how it works step by step:
- Prompt encoding – Your input question (the prompt) is converted into a numerical representation by an embedding model.
- Similarity search – This embedding vector is compared to entries in a vector database, which stores knowledge chunks (documents, paragraphs, text snippets) as vectors.
- Result selection – The retriever finds the most similar entries and returns the most relevant documents to be passed to the generator.
There are several factors that must be considered during the information retrieval process, as they can significantly impact the final results:
- Relevance – Only documents closest to the query (semantically similar) in vector space should be returned. Closeness is typically measured by a scalar value representing the distance between vectors.
- Controlling result count – Returning thousands of documents is inefficient and wastes tokens in the LLM’s context window.
- Avoiding under-retrieval – Returning just a single document may cause loss of valuable context.
- Determinism – Many retrieval algorithms are non-deterministic, meaning results may vary slightly between identical queries (more on this later).
In the next sections, we’ll explore common retrieval strategies, from classic keyword matching to modern vector-based methods, and how they can be combined for optimal results.
Ready to see how RAG transforms business workflows?
Meet directly with our founders and PhD AI engineers. We will demonstrate real implementations from 30+ agentic projects and show you the practical steps to integrate them into your specific workflows—no hypotheticals, just proven approaches.
Keyword Search
The first and simplest retrieval method is keyword search, which looks for documents that contain specific words mentioned in the user query. This approach is based on traditional text-matching techniques and is widely used in search engines. Two popular algorithms within this category are TF-IDF and BM25.
What is TF-IDF?
TF-IDF (Term Frequency–Inverse Document Frequency) is a classical statistical method for measuring the importance of words in a document relative to a collection (corpus) of documents. Instead of using dense vectors like in modern neural networks, TF-IDF uses sparse vectors where each feature represents a specific word in the vocabulary. It consists of two main components:
- Term Frequency (TF) – measures how frequently a term appears in a document:
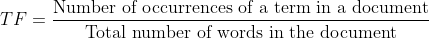
This alone, however, favors longer documents that naturally contain more keywords. To address this, we introduce the second component:
- Inverse Document Frequency (IDF) – measures how rare a term is across all documents:
")
The final TF-IDF score is the product of these two values: TF*IDF
This ensures that commonly used words (e.g., “the”, “and”) receive lower importance, while more distinctive terms contribute more to the overall document score.

What is BM25?
BM25 is an advanced ranking function that builds upon TF-IDF. It was developed by the same authors and introduces improvements to better handle document length and term saturation. Key enhancements over TF-IDF:
- Saturation effect – prevents a term that appears very frequently from disproportionately dominating the score.
- Length normalization – avoids favoring longer documents just because they include more words.
The BM25 scoring formula looks like this:
")
Where:
- k1 – saturation effect
- b – normalization of document length
While the IDF part remains similar to TF-IDF, these additional terms allow for fine-tuning how much term frequency and document length influence the final score. This makes BM25 more robust and effective for real-world information retrieval tasks.

Semantic Search
Semantic search is a more advanced retrieval technique compared to the keyword-based search. Instead of relying on exact word matches, it aims to understand the meaning behind a user’s query and the content of documents. It does this by mapping text into a high-dimensional vector space, where the semantic similarity between pieces of text can be measured mathematically. This allows a semantic search system to recognize that phrases like “buying a house” and “purchasing a home” refer to the same concept, even though they don’t share the exact wording.
How does semantic search work?
The process of semantic search typically involves the following steps:
- Text-to-vector conversion: Both the query and documents are transformed into fixed-length vectors (also called embeddings) using a neural embedding model trained to capture the meaning of language.
- Vector similarity calculation: The system compares the query vector to each document vector using similarity metrics such as:
- Cosine similarity – measures the angle between vectors
- Dot product – measures the projection of one vector onto another
- Euclidean distance – measures the straight-line distance between vectors
- Retrieval of semantically relevant documents: The most similar vectors (i.e. closest in meaning) are returned as the top relevant results, regardless of whether they share any specific keywords with the query.
This method is especially powerful in cases where:
- The vocabulary between the query and the documents differs (e.g., synonyms)
- The wording is imprecise or vague
- More abstract or conceptual information is being sought
What is a vector space?
At the core of semantic search lies the vector space – a mathematical abstraction where each piece of text is represented as a point in a high-dimensional space. In this space, semantically similar texts are positioned closer together, while unrelated ones are further apart. The number of dimensions typically ranges from 128 to 4096, depending on the embedding model used, making it a structure that’s difficult to visualize but highly effective for capturing the nuances of meaning.

What are embedding models?
To map text into a vector space, we use embedding models. These are neural networks trained to understand language and represent its meaning in numerical form. There are several types:
- Static embeddings (e.g., Word2Vec, GloVe): Produce a fixed vector for each word, regardless of context.
- Contextual embeddings (e.g., BERT, RoBERTa, OpenAI’s Ada): Generate vectors based on the meaning of a word in context, making them more powerful and accurate for semantic tasks.
In modern retrieval-augmented generation (RAG) systems, contextual embeddings are the default choice, as they can capture nuances, disambiguate meanings, and work well across various domains.
Hybrid Search
Hybrid search combines the strengths of both the keyword-based and semantic search approaches to deliver results that are both lexically accurate and semantically relevant. This method allows for more robust and flexible retrieval, especially in complex queries where either keywords or semantics alone may fall short. In a typical hybrid setup, both search methods are executed independently. Each returns its own set of top-ranked results (commonly referred to as $top_k$), which are then passed into a fusion mechanism, which merges and reorders them to produce a unified, optimized output. One popular and effective method for this merging process is Reciprocal Rank Fusion (RRF). Let’s take a closer look at how it works:
What is Reciprocal Rank Fusion (RRF)?
Reciprocal Rank Fusion is a simple yet powerful algorithm used to combine results from multiple ranked lists. It works by assigning a combined score to each document based on its position (rank) in the individual search result lists. The formula for calculating the RRF score is:
")
- d – document being scored
- r-i(d) – rank of document in the i-th ranked list
- list n – is the place in list created by retrieving information by a certain method
- k – smoothing parameter used to reduce the dominance of top-ranked items
The key idea is that documents appearing high in any list get a higher score, while still allowing contributions from documents that may not be at the very top but are ranked reasonably well across multiple sources. RRF is particularly valuable in hybrid search because it can elegantly balance precise keyword matches with semantically relevant content, providing the user with the most comprehensive and meaningful results.
Metadata Filtering
Metadata filtering is a complementary search mechanism that allows for the narrowing down of retrieved documents based on specific metadata attributes – such as title, author, publication date, category, or any other predefined tag. Instead of analyzing the content of documents directly, this method applies strict filters to eliminate irrelevant results early on in the pipeline. For example, a query could be limited only to documents published after 2022 or written by a specific author.
Advantages
- Simple and transparent – Easy to understand, implement, and debug.
- Fast and reliable – Often uses indexed fields, allowing filtering to be highly optimized.
- Deterministic – Guarantees that certain constraints are strictly enforced (e.g., only recent data or domain-specific documents).
Limitations
- Not a true search method – It doesn’t evaluate semantic or lexical relevance, only metadata.
- Discards potentially useful content – May exclude high-quality documents simply because they fall outside the filter range.
- Ineffective alone – Cannot rank or evaluate content by itself and therefore must be combined with full retrieval or ranking mechanisms (e.g., semantic search or hybrid search).
In practice, metadata filtering works best as a pre-filtering step in a more complex retrieval system-tightening the scope before applying semantic or keyword-based ranking to ensure higher precision and relevance.
IR in RAG systems in short
To build the most robust and effective information retrieval (IR) component in your retrieval-augmented generation (RAG) pipeline, it needs to be fine-tuned with a complex series to produce the most valuable results. This begins with pre-filtering results with metadata filtering to narrow results from a wide selection of relevant documents, which is then passed through a semantic, keyword, or (ideally) hybrid search to deliver results that are both lexically accurate and semantically relevant. For an expert consultation sharing experience drawn from hands-on application of complex and robust RAG systems, our experts at Vstorm are available for a call.
Ready to see how RAG transforms business workflows?
Meet directly with our founders and PhD AI engineers. We will demonstrate real implementations from 30+ agentic projects and show you the practical steps to integrate them into your specific workflows—no hypotheticals, just proven approaches.
Bibliography
https://docs.opensearch.org/latest/search-plugins/keyword-search/ https://www.geeksforgeeks.org/nlp/what-is-bm25-best-matching-25-algorithm/ https://www.elastic.co/what-is/semantic-search https://supabase.com/docs/guides/ai/hybrid-search
Summarize with AI
The LLM Book
The LLM Book explores the world of Artificial Intelligence and Large Language Models, examining their capabilities, technology, and adaptation.




