Dynamic Tool Discovery: A Systematic Evaluation of 8 Search Strategies for AI Agents


The proliferation of tools in AI agent systems creates a context bloat problem: providing an agent with 51 tools consumes 18,492 tokens per query. This study presents a comparison of 8 tool discovery strategies for dynamic tool discovery. We evaluated keyword-based methods (regex, BM25), semantic approaches (RAG with Pinecone, Milvus, cross-encoder), and hybrid fusion (BM25+RAG with RRF) across 100 queries in both one-shot and multi-turn conversation modes using GPT-4o-mini. For tools following recommended naming conventions, keyword methods (94% accuracy) matched or outperformed semantic search (93%) and hybrid approaches (90.5%). The best-performing dynamic strategy (regex) achieved 95% accuracy with 73% token reduction compared to the all-tools baseline (99% accuracy). Our results align with Anthropic’s guidance on tool design: when tools follow recommended naming conventions (service-prefixed, action-suffixed), the naming itself provides sufficient signal for discovery, reducing the need for semantic understanding.
The Context Bloat Problem
Modern AI agent systems increasingly rely on external tools to extend their capabilities beyond pure language modeling. Production systems now commonly integrate dozens to hundreds of tools spanning messaging (Slack), productivity (Calendar, Email), code management (GitHub, Jira), entertainment (Spotify), and more. However, this capability expansion creates a fundamental scalability challenge: context bloat.
In our experimental setup, providing an agent with 51 tool definitions consumes 18,492 tokens per query on average. At scale, this represents a three-fold problem:
- Cost: At GPT-4o-mini pricing ($0.15/1M input tokens), processing 10,000 queries with all tools costs $28.35 versus $8.03 with optimized retrieval-a 3.5x cost multiplier.
- Context competition: Tool definitions compete with actual conversation content, user instructions, and retrieved documents for limited context window space.
- Cognitive load: LangChain’s benchmarking found “a significant decrease in performance with increased context-size, even if that context was irrelevant to the target task.”
This problem is not theoretical. Anthropic’s production systems have encountered token budgets exceeding 134,000 tokens when managing extensive MCP (Model Context Protocol) tool collections.
Research Questions
This study addresses four research questions:
- RQ1: How do different retrieval strategies compare for tool discovery in terms of accuracy and token efficiency?
- RQ2: Does semantic search outperform keyword-based methods for tool retrieval?
- RQ3: Do hybrid approaches that combine lexical and semantic signals achieve better results than either method alone?
- RQ4: How does conversation context (multi-turn dialogues) affect retrieval performance?
Contributions
This work makes the following contributions:
- Systematic comparison: The first rigorous evaluation of 8 retrieval strategies specifically for tool discovery, spanning keyword, semantic, and hybrid approaches.
- Counter-intuitive evidence: Empirical demonstration that keyword-based methods outperform semantic search for tool retrieval, contradicting common assumptions in the RAG literature.
- Hybrid paradox analysis: Investigation of why hybrid fusion underperforms its component methods, contrary to expectations from document retrieval research.
- Practical recommendations: Decision framework mapping use cases to optimize strategies, grounded in quantitative trade-off analysis.
Related Works
Tool Search in Production
Anthropic has introduced the Tool Search Tool pattern for managing large tool collections, reporting:
“This represents an 85% reduction in token usage while maintaining access to your full tool library. […] Opus 4 improved from 49% to 74%.” – Anthropic
Their approach uses an LLM-in-the-loop architecture where the model itself generates search queries to discover relevant tools. This pattern inspired our investigation but differs from our focus on comparing retrieval algorithms.
Warnings Against RAG for Tools
Phil Schmid explicitly cautions against semantic retrieval for tool definitions:
“Fetching tool definitions dynamically per step based on semantic similarity often fails. It creates a shifting context that breaks the KV cache and confuses the model with ‘hallucinated’ tools that were present in turn 1 but disappeared in turn 2.” – Phil Schmid
This warning informed our hypothesis that semantic approaches might underperform keyword methods for the structured, nomenclature-dense domain of tool definitions.
Multi-Agent Comparisons
LangChain’s benchmarking of multi-agent architectures found that single-agent performance degrades significantly with increasing tool count, particularly when “distractor domains” introduce unrelated tools. Their findings suggest tool discovery is a critical bottleneck, though they did not systematically compare retrieval strategies.
Vstorm’s Methodology
Experimental Setup
Experiment Configuration
|
Parameter |
Value |
|
Total tools |
51 across 16 categories |
|
Test queries |
100 (ranging from single to multi-tool) |
|
Evaluation modes |
One-shot, Conversation (5-turn batches) |
|
LLM |
GPT-4o-mini (OpenAI) |
|
Embedding model |
text-embedding-3-large (3,072 dimensions) |
|
Top-k retrieval |
5 tools per search |
|
Vector databases |
Pinecone, Milvus |
All tools were mock implementations with realistic signatures and docstrings, simulating a production assistant with capabilities across Slack, Spotify, Calendar, Weather, GitHub, Jira, Email, Shopping, Contacts, Files, Documents, Notes, Reminders, Timezone, Translation, and Calculator domains.
Query dataset construction: 100 test queries were manually authored based on the available tool definitions. For each tool, we crafted example queries that a user might realistically give to an assistant, ranging from single-tool requests (e.g., “Check the weather in New York“) to multi-tool compositions requiring 2–3 tools in sequence (e.g., “Find the email about Q4 Planning, mark it as read, and reply“). Each query was annotated with expected tool(s) and a reference answer.
Search Strategies
We evaluated 8 strategies spanning three categories:
Strategy Implementations
|
Strategy |
Category |
Implementation Details |
|
|
Baseline |
All 51 tools loaded into context |
|
|
Keyword |
Weighted scoring: +10 phrase match, +5 name match, +2 description match |
|
|
Keyword |
BM25 ranking via bm25s library with PyStemmer |
|
|
Semantic |
Pinecone vector search with OpenAI embeddings |
|
|
Semantic |
Milvus vector search with OpenAI embeddings |
|
|
Semantic |
ms-marco-MiniLM-L-6-v2 reranker scoring all pairs |
|
|
Hybrid |
BM25 + Pinecone with RRF fusion (k=60) |
|
|
Hybrid |
BM25 + Milvus with RRF fusion (k=60) |
Search Strategy Characteristics
|
Strategy |
Search Latency |
External API |
Infrastructure |
Initialization |
|
|
~0ms |
None |
None |
Instant |
|
|
~10ms |
None |
None |
~100ms (tokenization) |
|
|
~50–100ms |
None |
None |
~2s (model load) |
|
|
~200–500ms |
OpenAI Embeddings |
Pinecone (cloud) |
~500ms |
|
|
~200–500ms |
OpenAI Embeddings |
Milvus (Docker) |
~500ms |
|
|
~300–600ms |
OpenAI Embeddings |
Pinecone (cloud) |
~600ms |
|
|
~300–600ms |
OpenAI Embeddings |
Milvus (Docker) |
~600ms |
Metrics
Primary metrics:
- Accuracy: Binary classification-did the agent call at least one expected tool?
- Total tokens: Sum of input and output tokens per query
Secondary metrics:
- Duration (seconds)
- API requests count
- Tool calls count
Statistical tests:
- Two-sample t-test for mean comparisons
- Mann-Whitney U test for non-parametric validation
- Cohen’s d for effect size quantification
Tool Categories
The 51 tools were distributed across 16 categories:
|
Category |
Tool Count |
Example Tools |
|
Slack |
5 |
|
|
Spotify |
7 |
|
|
Calendar |
3 |
|
|
|
5 |
|
|
GitHub |
4 |
|
|
Jira |
5 |
|
|
Shopping |
4 |
|
|
Files |
3 |
|
|
Documents |
3 |
|
|
Notes |
2 |
|
|
Weather |
3 |
|
|
Contacts |
2 |
|
|
Reminders |
2 |
|
|
Timezone |
1 |
|
|
Translate |
1 |
|
|
Calculator |
1 |
|
Results
Accuracy Analysis
One-Shot Accuracy Rankings
|
Rank |
Strategy |
Accuracy |
Correct/Total |
|
1 |
all_tools |
99.0% |
99/100 |
|
2 |
regex |
95.0% |
95/100 |
|
2 |
cross_encoder |
95.0% |
95/100 |
|
4 |
pinecone |
94.0% |
94/100 |
|
5 |
bm25 |
93.0% |
93/100 |
|
6 |
hybrid_milvus |
92.0% |
92/100 |
|
7 |
milvus |
90.0% |
90/100 |
|
8 |
hybrid_pinecone |
89.0% |
89/100 |
Key observations:
- The baseline (
all_tools) achieved near-perfect accuracy (99%), establishing an upper bound. - Dynamic strategies ranged from 89% to 95% accuracy-a 4-10 percentage point gap from baseline.
- Hybrid approaches ranked last among dynamic strategies, contradicting expectations that combining signals would improve results. Our hybrid implementation uses Reciprocal Rank Fusion (RRF): both BM25 and semantic search independently retrieve
top_k × 3candidates, then their rankings are merged using weighted1/(k + rank)scoring with equal 50/50 weights. When the two rankers disagree—e.g., keyword correctly ranksdocuments_sharefirst while semantic surfacesfiles_share—RRF averages the conflicting ranks, potentially demoting the correct tool below the top-k cutoff. We analyze this effect in detail in Section 5.2. - The simplest keyword method (
regex) tied for best dynamic performance despite minimal computational overhead.
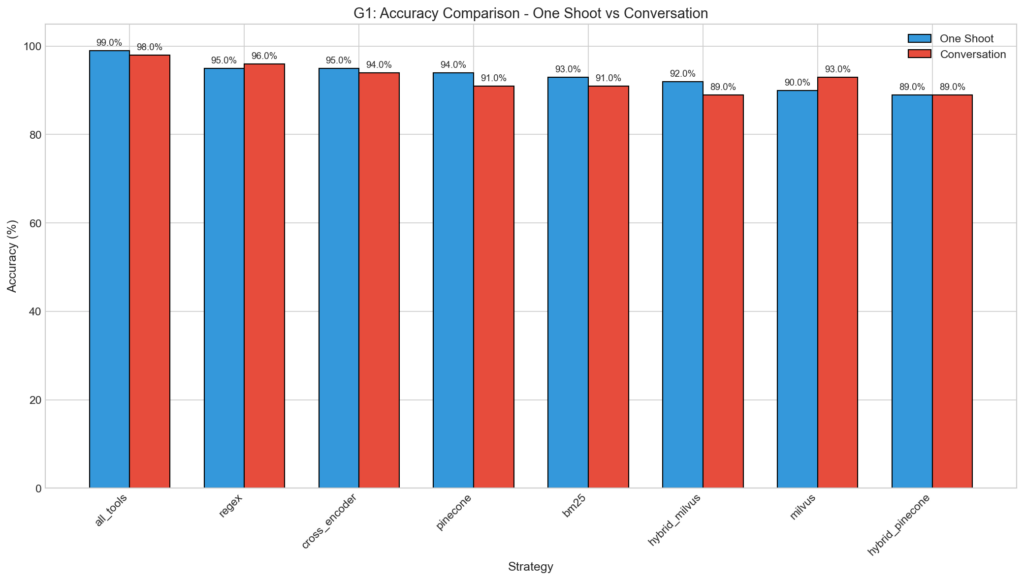
Grouped bar chart comparing accuracy across one-shot and conversation modes for all strategies.
Token Efficiency
Token Usage Comparison
|
Strategy |
Avg Tokens |
Std Dev |
Min |
Max |
Reduction vs Baseline |
|
regex |
4,986 |
2,702 |
1,976 |
18,311 |
73.0% |
|
cross_encoder |
5,643 |
3,374 |
2,319 |
20,049 |
69.5% |
|
hybrid_pinecone |
5,886 |
4,492 |
0 |
28,477 |
68.2% |
|
hybrid_milvus |
5,961 |
4,445 |
0 |
30,801 |
67.8% |
|
milvus |
5,967 |
4,824 |
0 |
29,435 |
67.7% |
|
bm25 |
6,728 |
8,132 |
2,290 |
75,406 |
63.6% |
|
pinecone |
7,459 |
6,786 |
2,298 |
41,054 |
59.7% |
|
all_tools |
18,492 |
9,224 |
10,711 |
72,004 |
— |
All dynamic strategies achieved 60-73% token reduction compared to baseline. The regex strategy was most efficient, using 3.7x fewer tokens than all_tools.
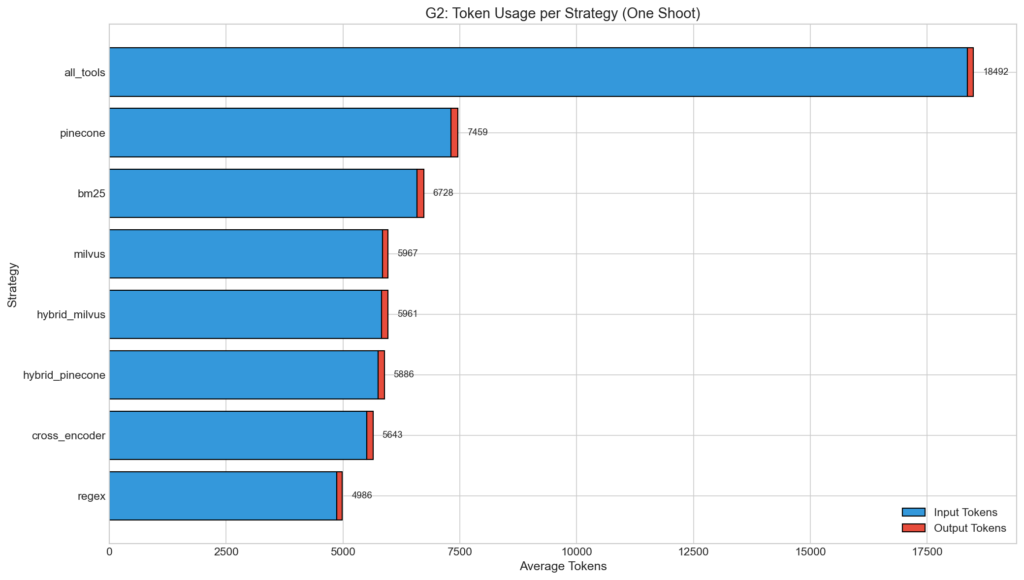
Stacked bar chart showing input/output token breakdown per strategy.
Statistical significance: The difference between all_tools and all dynamic strategies was highly significant (p < 0.001, Cohen’s d > 1.3 “Large” effect size for all comparisons).
Statistical Significance (Token Comparison)
|
Comparison |
Mean Diff |
T-statistic |
p-value |
Cohen’s d |
Effect Size |
|
all_tools vs regex |
13,506 |
14.05 |
< 0.001 |
1.99 |
Large |
|
all_tools vs cross_encoder |
12,849 |
13.08 |
< 0.001 |
1.85 |
Large |
|
all_tools vs hybrid_pinecone |
12,606 |
12.29 |
< 0.001 |
1.74 |
Large |
|
all_tools vs hybrid_milvus |
12,530 |
12.24 |
< 0.001 |
1.73 |
Large |
|
all_tools vs milvus |
12,525 |
12.03 |
< 0.001 |
1.70 |
Large |
|
all_tools vs bm25 |
11,764 |
9.57 |
< 0.001 |
1.35 |
Large |
|
all_tools vs pinecone |
11,033 |
9.64 |
< 0.001 |
1.36 |
Large |
|
regex vs pinecone |
-2,473 |
-3.39 |
0.001 |
-0.48 |
Small |
|
regex vs bm25 |
-1,742 |
-2.03 |
0.044 |
-0.29 |
Small |
Strategy Type Comparison
Aggregating by strategy type reveals clear patterns:
Performance by Strategy Type (One-Shot)
|
Type |
Strategies |
Avg Accuracy |
Avg Tokens |
Avg Duration |
|
Baseline |
all_tools |
99.0% |
18,492 |
5.30s |
|
Keyword |
regex, bm25 |
94.0% |
5,857 |
5.60s |
|
Semantic |
pinecone, milvus, cross_encoder |
93.0% |
6,356 |
6.52s |
|
Hybrid |
hybrid_pinecone, hybrid_milvus |
90.5% |
5,924 |
6.45s |
Finding: Keyword (94.0%) > Semantic (93.0%) > Hybrid (90.5%)
This contradicts the assumption that semantic understanding of query intent would improve tool matching. Keyword methods’ advantage likely stems from tool naming conventions that embed functional keywords directly in identifiers.
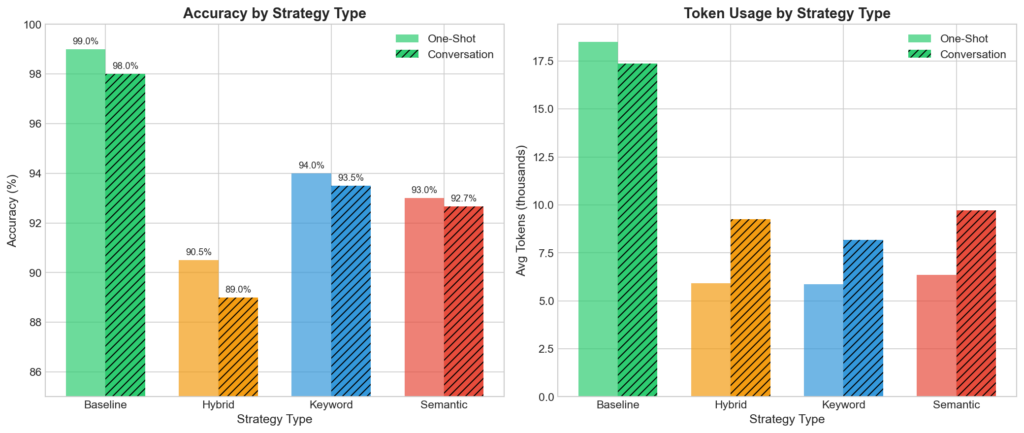
Side-by-side comparison of strategy types showing accuracy and token usage for one-shot vs conversation modes.
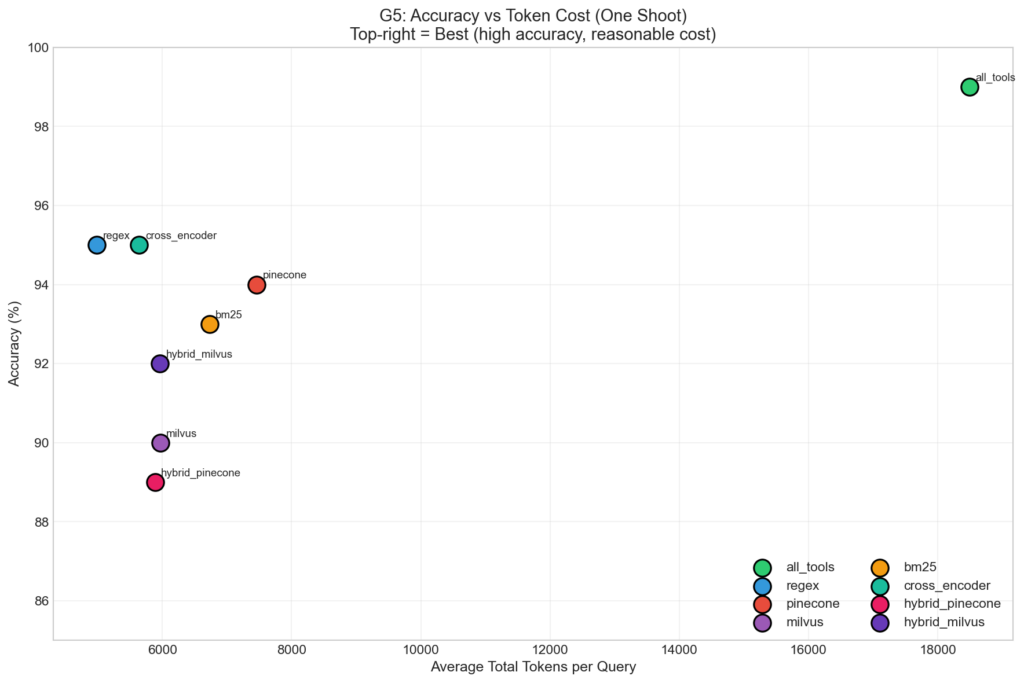
Scatter plot showing accuracy vs token cost trade-off, identifying the Pareto frontier.
Conversation Mode Impact
We evaluated multi-turn conversations where context accumulates across 5 messages.
Context Growth Rate (Message 1 → Message 5)
|
Strategy |
Tokens Msg 1 |
Tokens Msg 5 |
Total Growth (%) |
Avg Growth Rate |
|
all_tools |
18,302 |
20,150 |
+10.1% |
3.67% per msg |
|
bm25 |
7,412 |
12,343 |
+66.5% |
17.20% per msg |
|
hybrid_milvus |
6,348 |
11,383 |
+79.3% |
15.88% per msg |
|
hybrid_pinecone |
6,771 |
13,111 |
+93.6% |
19.07% per msg |
|
cross_encoder |
5,344 |
11,266 |
+110.8% |
21.16% per msg |
|
milvus |
6,737 |
14,384 |
+113.5% |
21.33% per msg |
|
regex |
4,893 |
10,834 |
+121.4% |
23.04% per msg |
|
pinecone |
5,518 |
14,150 |
+156.5% |
36.00% per msg |
Key insight: While dynamic strategies have higher relative growth rates, the absolute token counts remain substantially lower than baseline throughout the conversation. Growth is linear, not exponential.
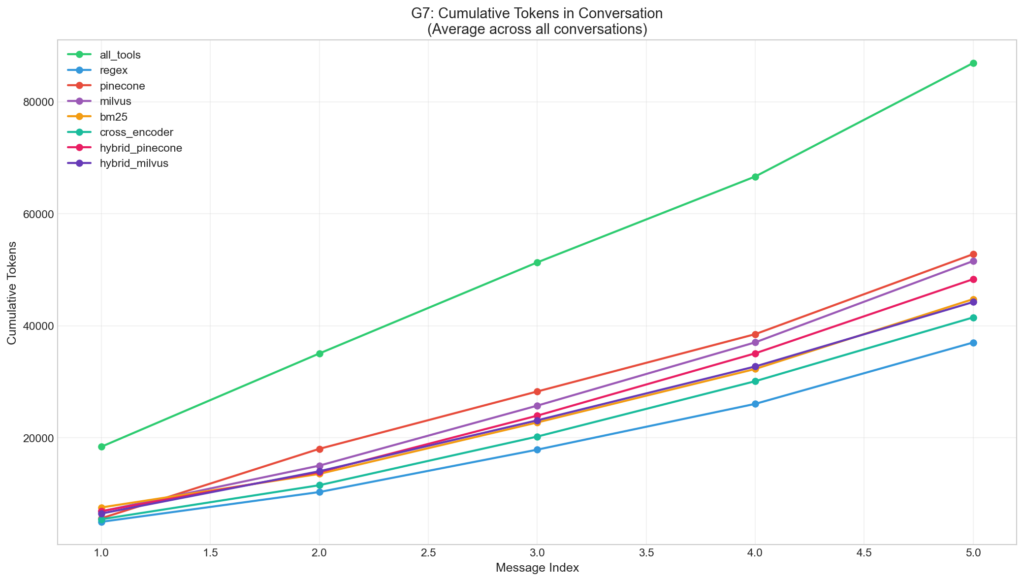
Line chart showing cumulative token usage across conversation turns.
Accuracy by Message Position (Conversation Mode)
|
Message Index |
all_tools |
regex |
pinecone |
milvus |
cross_encoder |
bm25 |
hybrid_pinecone |
hybrid_milvus |
|
1 |
90.0% |
90.0% |
95.0% |
100.0% |
90.0% |
85.0% |
85.0% |
85.0% |
|
2 |
100.0% |
100.0% |
90.0% |
90.0% |
100.0% |
95.0% |
90.0% |
90.0% |
|
3 |
100.0% |
95.0% |
80.0% |
85.0% |
85.0% |
90.0% |
85.0% |
85.0% |
|
4 |
100.0% |
95.0% |
95.0% |
95.0% |
95.0% |
90.0% |
90.0% |
90.0% |
|
5 |
100.0% |
100.0% |
95.0% |
95.0% |
100.0% |
95.0% |
95.0% |
95.0% |
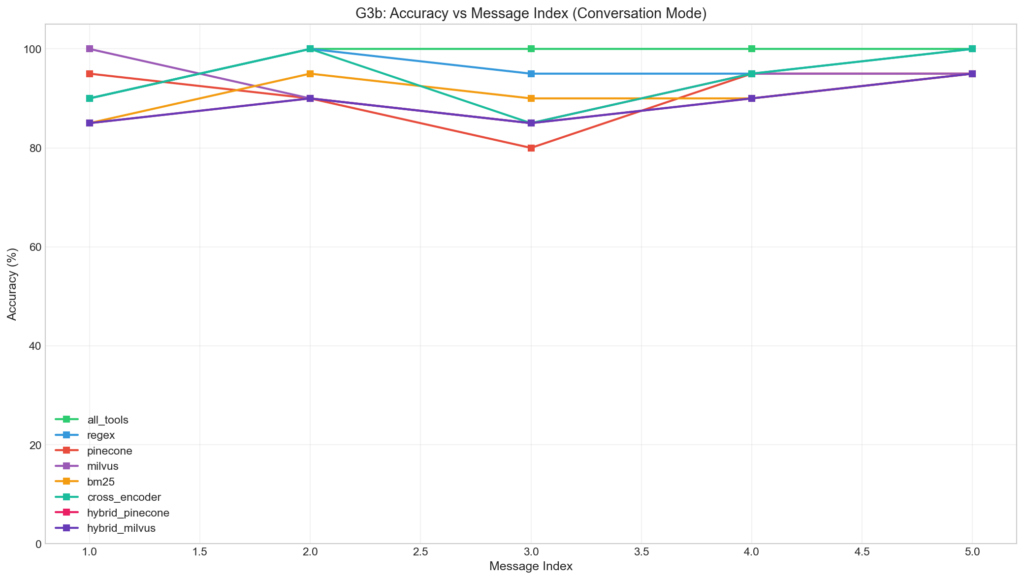
Line chart showing accuracy changes across conversation turns.
Accuracy Delta (Conversation – One-Shot)
|
Strategy |
One-Shot |
Conversation |
Delta |
Direction |
|
milvus |
90.0% |
93.0% |
+3pp |
↑ Better |
|
regex |
95.0% |
96.0% |
+1pp |
↑ Better |
|
hybrid_pinecone |
89.0% |
89.0% |
0pp |
= Same |
|
all_tools |
99.0% |
98.0% |
-1pp |
↓ Worse |
|
cross_encoder |
95.0% |
94.0% |
-1pp |
↓ Worse |
|
bm25 |
93.0% |
91.0% |
-2pp |
↓ Worse |
|
pinecone |
94.0% |
91.0% |
-3pp |
↓ Worse |
|
hybrid_milvus |
92.0% |
89.0% |
-3pp |
↓ Worse |
Conversation mode had mixed effects: some strategies improved (milvus, regex) while others degraded (pinecone, hybrid_milvus). This suggests conversation context can either help (by providing disambiguation cues) or hurt (by introducing noise).
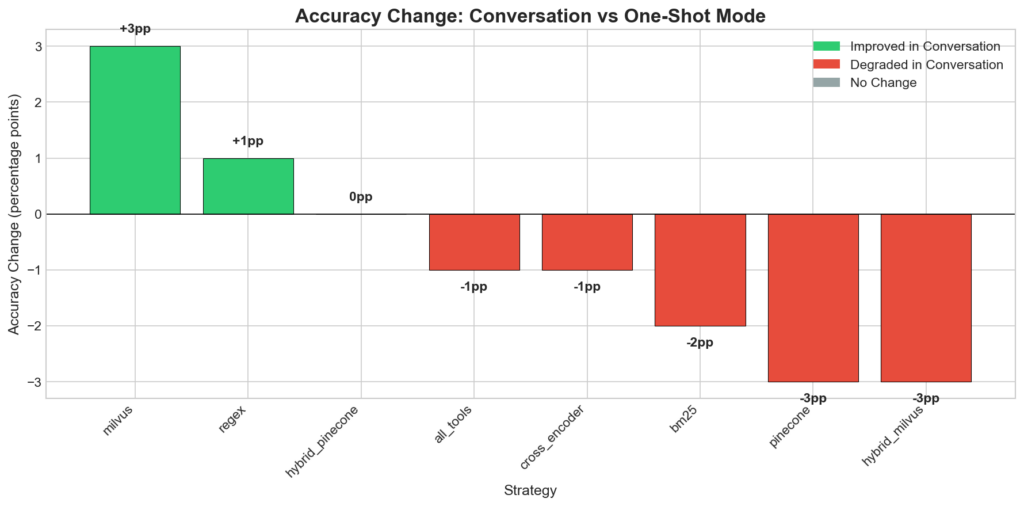
Waterfall chart showing accuracy changes between one-shot and conversation modes.
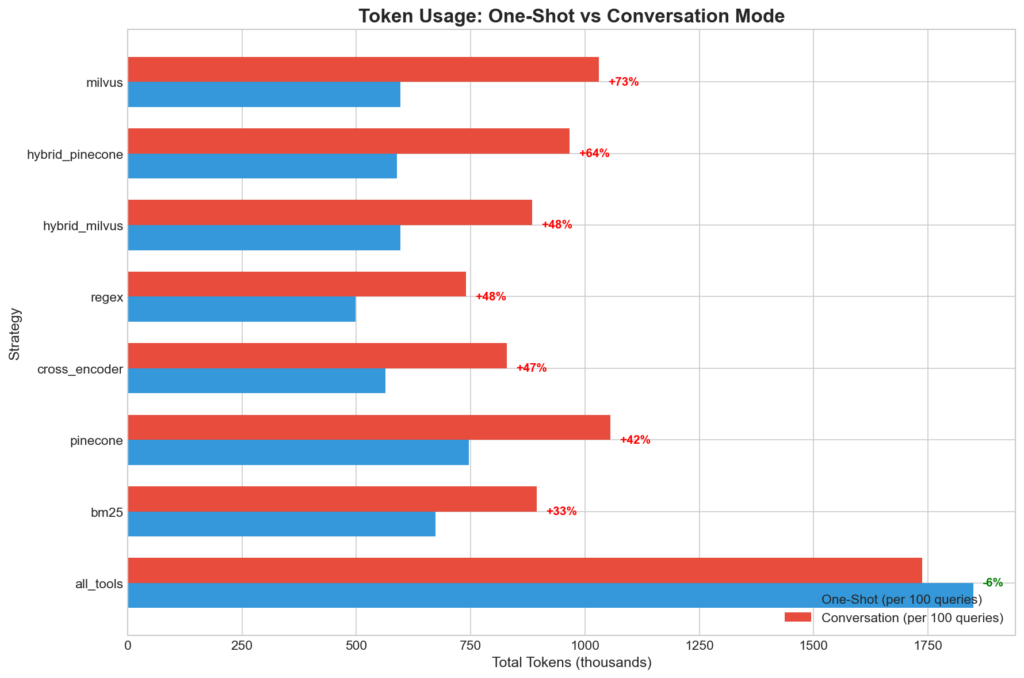
Horizontal bar chart comparing token overhead between modes.
Failure Analysis
Accuracy by Tool Category
Hardest Categories (Aggregated Across All Strategies)
|
Category |
Avg Accuracy |
Sample Size |
Best Strategy |
Worst Strategy |
Challenge |
|
documents |
81.2% |
4 |
pinecone, milvus (100%) |
all others (75%) |
Semantic methods excel on naming-ambiguous queries |
|
notes |
77.1% |
12 |
all_tools (100%) |
hybrid_rag, milvus (66.7%) |
Ambiguous with documents/files |
|
spotify |
77.7% |
14 |
all_tools (100%) |
hybrid_pinecone, milvus (64.3%) |
Multi-tool queries complexity |
|
github |
90.9% |
11 |
all_tools, regex, bm25 (100%) |
hybrid_pinecone (82%) |
Technical terminology |
|
weather |
95.8% |
9 |
all_tools, regex, pinecone, milvus, cross_encoder (100%) |
bm25 (88%) |
— |
|
timezone |
95.8% |
3 |
most (100%) |
milvus (50%) |
Single outlier |
|
translate |
93.8% |
2 |
most (100%) |
regex (50%) |
Single outlier |
|
slack |
93.8% |
24 |
most (100%) |
hybrid_pinecone (89%) |
— |
|
calculator |
97.5% |
10 |
all (100%) |
— |
Unambiguous domain |
|
calendar |
100.0% |
9 |
all (100%) |
— |
Unambiguous domain |
|
contacts |
100.0% |
4 |
all (100%) |
— |
Unambiguous domain |
|
|
96.5% |
18 |
all (100%) |
— |
— |
|
files |
97.9% |
12 |
all (100%) |
— |
— |
|
jira |
98.9% |
11 |
all (100%) |
— |
— |
|
reminders |
100.0% |
9 |
all (100%) |
— |
Unambiguous domain |
|
shopping |
100.0% |
13 |
all (100%) |
— |
Unambiguous domain |
Key insight on documents category: While overall accuracy is 81.2%, semantic methods (pinecone, milvus) achieve 100% accuracy compared to 75% for all other strategies. The critical difference appears on queries with naming ambiguity-for example, “Find the ‘Design Mockups.fig’ file” requires documents_list but non-semantic methods match files_search due to the word “file” in the query. This demonstrates that for categories with naming overlap (documents vs files), semantic understanding provides measurable benefit.
Implication: Tool naming conventions matter more than search algorithm choice. When tool names are unambiguous (e.g., slack_*, calendar_*), all strategies achieve near-perfect accuracy. The performance gap emerges only when semantic boundaries do not align with lexical signals.
Accuracy by Query Complexity
Performance vs Expected Tools Count
|
Expected Tools |
Query Count |
Best Strategy |
Worst Strategy |
Accuracy Range |
|
1 tool |
11 |
bm25, hybrid_milvus, hybrid_pinecone, milvus, pinecone (100%) |
regex, cross_encoder (90.9%) |
90.9–100% |
|
2 tools |
75 |
all_tools (98.7%) |
hybrid_pinecone (89.3%) |
89.3–98.7% |
|
3 tools |
14 |
all_tools, regex, cross_encoder (100%) |
hybrid_milvus, hybrid_pinecone, milvus (78.6%) |
78.6–100% |
Multi-tool queries showed higher variance. The hybrid strategies degraded most severely on 3-tool queries (78.6%), while regex and cross_encoder maintained 100% accuracy.
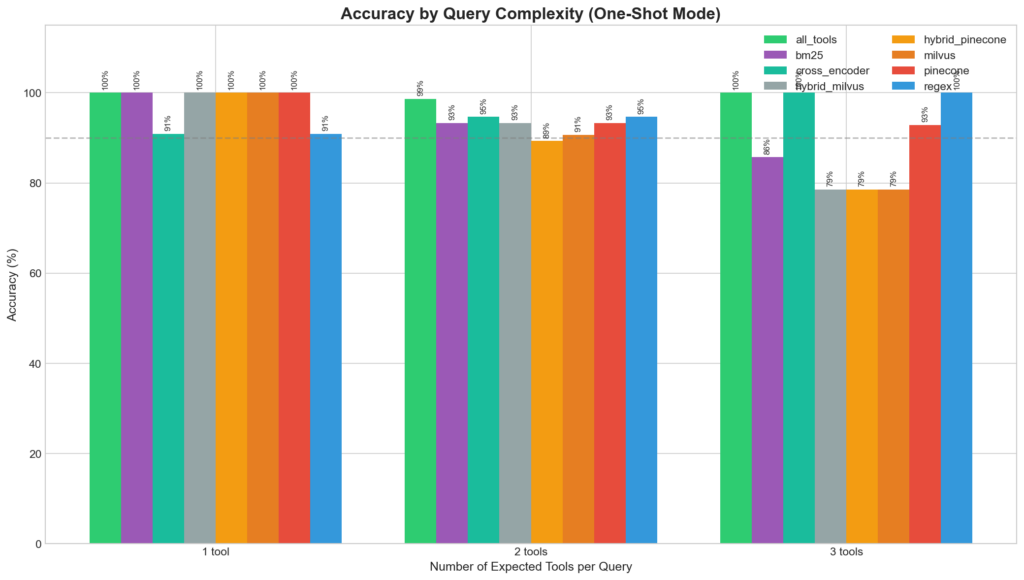
Grouped bar chart showing accuracy breakdown by query complexity (1, 2, 3 expected tools).
Tool Discovery Rate
Full Discovery Rate by Strategy
|
Strategy |
Full Discovery (%) |
Partial (%) |
No Discovery (%) |
|
all_tools |
78.0% |
21.0% |
1.0% |
|
cross_encoder |
58.0% |
37.0% |
5.0% |
|
regex |
56.0% |
39.0% |
5.0% |
|
pinecone |
53.0% |
41.0% |
6.0% |
|
bm25 |
51.0% |
42.0% |
7.0% |
|
hybrid_pinecone |
51.0% |
38.0% |
11.0% |
|
milvus |
51.0% |
39.0% |
10.0% |
|
hybrid_milvus |
48.0% |
44.0% |
8.0% |
False Positive Analysis
False Positive Rates by Strategy
|
Strategy |
Avg False Positives |
Max FP |
% Queries with FP |
Total FP |
|
all_tools |
0.33 |
2 |
29.0% |
33 |
|
regex |
1.43 |
5 |
100.0% |
143 |
|
cross_encoder |
1.50 |
5 |
100.0% |
150 |
|
hybrid_pinecone |
1.67 |
4 |
99.0% |
167 |
|
bm25 |
1.69 |
7 |
100.0% |
169 |
|
hybrid_milvus |
1.70 |
4 |
99.0% |
170 |
|
milvus |
1.70 |
5 |
97.0% |
170 |
|
pinecone |
1.80 |
5 |
100.0% |
180 |
Dynamic strategies consistently retrieved ~1.5 irrelevant tools per query (from top-k=5), but this did not significantly impact accuracy – the LLM correctly ignored irrelevant tools.
Most Frequently Retrieved False Positives:
|
Tool |
False Positive Count |
Why Retrieved |
|
|
695 |
Agent’s search function (expected overhead) |
|
|
52 |
Triggered by any music-related query |
|
|
43 |
Triggered by “add” + music context |
|
|
40 |
Triggered by any “send to person” query |
|
|
37 |
Triggered by project/issue terminology |
|
|
32 |
Triggered by “find”/”search” + document context |
The search_tools meta-tool dominates false positives (695 calls across all strategies), confirming that dynamic agents actively utilize the search capability ~7 searches per query across all strategies on average.
Worst-Performing Queries
Analysis of queries that failed across multiple strategies reveals systematic failure patterns:
Hardest Queries (Sorted by Failure Count)
|
Query (truncated) |
Expected Tools |
Failures |
Passed |
Root Cause |
|
“Find the note about ‘Project Ideas’…” |
notes_search, notes_create |
7/8 |
all_tools |
|
|
“Find ‘Design Mockups.fig’ file…” |
documents_list, slack_send_dm |
6/8 |
pinecone, milvus |
Word “file” triggers |
|
“Find ‘casual’ playlist, Shuffle it…” |
spotify_get_playlist, notes_create |
5/8 |
all_tools, bm25, cross_encoder |
Mock pattern (shuffle → notes) confuses keyword |
|
“Check if ‘Deep Focus’ in playlist…” |
spotify_get_playlist, spotify_add_to_playlist, spotify_search |
5/8 |
all_tools, regex, cross_encoder |
Multi-tool Spotify queries |
|
“Check if ‘Study Session’ track exists…” |
spotify_search, spotify_play, notes_create |
4/8 |
all_tools, regex, pinecone, cross_encoder |
Complex 3-tool chain |
Key failure patterns:
- Naming collision: Queries containing “file” when
documents_*tools are expected - Multi-tool complexity: 3+ tool queries have higher variance
- Mock patterns: Non-standard workarounds (e.g. using
notes_createto simulate shuffle) confuse retrieval
Strategic implications:
all_toolsbaseline passes most edge cases (7/8 strategies failed → all_tools passed)- Semantic methods (pinecone, milvus) uniquely pass the
documentsqueries where keyword fails - Cross-encoder shows robustness on complex Spotify queries despite being semantic
Discussion
Why Keyword Beats Semantic
Three factors explain the counter-intuitive superiority of keyword methods:
1. Tools are designed artifacts with explicit nomenclature.
Unlike natural documents where concepts may be expressed in varied ways, tool names and descriptions are deliberately crafted with discoverable keywords: slack_send_message, calendar_schedule_meeting, spotify_play_track. These explicit signals favor exact matching.
2. Semantic similarity ≠ functional equivalence.
A query about “documents” is semantically similar to “files” and “notes,” but these map to distinct tools with different capabilities. Semantic embeddings capture topical relatedness rather than functional boundaries, leading to cross-category confusion.
3. The “shifting context” problem applies to all dynamic strategies.
Phil Schmid warns about “shifting context” where “tools present in turn 1 disappear in turn 2,” confusing the model. While he attributes this to semantic retrieval specifically, our data suggests this is inherent to any dynamic tool selection—keyword methods included. In conversation mode, bm25 degraded by -2pp and pinecone by -3pp, showing that both sparse and dense retrieval suffer when the available toolset shifts between turns. The fundamental issue is not the retrieval algorithm but the dynamic nature of the toolset itself.
The Hybrid Paradox
Hybrid approaches were expected to combine the precision of keyword matching with the recall of semantic search. Reality proved otherwise:
Observed: Hybrid (90.5%) < Semantic (93.0%) < Keyword (94.0%)
However, the paradox is nuanced. Per-query analysis reveals asymmetric behavior:
|
Hybrid Strategy |
Better than Component |
Worse than Component |
Net Effect |
|
hybrid_pinecone vs pinecone |
3 queries |
3 queries |
Neutral |
|
hybrid_milvus vs milvus |
7 queries |
2 queries |
+5 net wins |
hybrid_milvus slightly outperforms milvus overall (92% vs 90%), likely because it wins more of the disagreement cases.
Hypothesis: Error amplification via RRF (applies primarily to hybrid_pinecone)
RRF assumes both rankers contribute complementary signals. However, when both rankers err in different directions, fusion produces a compromised ranking that inherits errors from both. In tool retrieval, where correct matches require high precision, this error blending is particularly harmful. Notably, RRF is rank-based and discards the original retrieval scores entirely—a different fusion method that incorporates score normalization or adaptive weighting could yield different results (see alternative architectures below).
Consider a query “share the budget document with Alice”:
- Keyword search correctly ranks
documents_sharehigh - Semantic search surfaces
files_shareandemail_send(semantically related to “sharing”) - RRF fusion averages the ranks, potentially demoting the correct tool
Revised recommendation: For Milvus users, hybrid_milvus may be preferable to pure milvus despite lower aggregate accuracy, as it wins on more individual queries.
Alternative architectures to explore:
- Learned weighting: Replace fixed 50/50 weighting with query-dependent weights learned from training data.
- Cascade architecture: Use keyword search first, falling back to semantic only when keyword retrieval returns low-confidence results.
- Query routing: Classify queries upstream and route to appropriate retriever based on query type (action-oriented → keyword, conceptual → semantic).
Practical Recommendations
Strategy Selection Guide
|
Use Case |
Recommended |
Accuracy |
Tokens |
Cost/100q |
Justification |
|
Maximum accuracy |
all_tools |
99% |
18,492 |
$0.28 |
Worth cost if tools < 15 |
|
Production scale |
regex |
95% |
4,986 |
$0.08 |
Best accuracy/token trade-off |
|
Semantic queries |
cross_encoder |
95% |
5,643 |
$0.09 |
No API dependency |
|
Zero external cost |
bm25 |
93% |
6,728 |
$0.11 |
Fully local, fast init |
|
Self-hosted vector |
milvus |
90% |
5,967 |
$0.10 |
Vector search without cloud |
Cost Analysis at Scale:
|
Queries |
all_tools Cost |
regex Cost |
Savings |
|
100 |
$0.28 |
$0.08 |
$0.20 (71%) |
|
10,000 |
$28.35 |
$8.03 |
$20.32 (72%) |
|
1,000,000 |
$2,835 |
$803 |
$2,032 (72%) |
Note on Embedding Costs: Pinecone/Milvus strategies incur additional OpenAI embedding API costs (~$0.13/1M tokens for text-embedding-3-large). At ~50 tokens per search query, this adds ~$0.0065 per 100 queries-negligible compared to LLM inference costs. However, for fully offline deployments, consider bm25 or cross_encoder which require no external APIs.
Cross-Model Cost Comparison:
The cost savings from dynamic tool discovery become even more significant with larger, more expensive models. Below we compare costs per 100 queries across four frontier models:
Model Pricing
|
Model |
Input ($/1M tokens) |
Output ($/1M tokens) |
|
GPT-4o-mini |
$0.15 |
$0.60 |
|
GPT-4o |
$2.50 |
$10.00 |
|
Claude 3.5 Sonnet |
$3.00 |
$15.00 |
|
Gemini 1.5 Pro |
$1.25 |
$5.00 |
Cost per 100 Queries by Model and Strategy
|
Strategy |
Avg Input |
Avg Output |
GPT-4o-mini |
GPT-4o |
Claude 3.5 Sonnet |
Gemini 1.5 Pro |
|
regex |
4,865 |
122 |
$0.08 |
$1.34 |
$1.64 |
$0.67 |
|
cross_encoder |
5,511 |
132 |
$0.09 |
$1.51 |
$1.85 |
$0.76 |
|
hybrid_pinecone |
5,754 |
132 |
$0.09 |
$1.58 |
$1.93 |
$0.79 |
|
hybrid_milvus |
5,825 |
136 |
$0.10 |
$1.59 |
$1.95 |
$0.80 |
|
milvus |
5,841 |
126 |
$0.10 |
$1.59 |
$1.94 |
$0.79 |
|
bm25 |
6,587 |
141 |
$0.11 |
$1.79 |
$2.19 |
$0.89 |
|
pinecone |
7,308 |
151 |
$0.12 |
$1.98 |
$2.42 |
$0.99 |
|
all_tools |
18,356 |
136 |
$0.28 |
$4.73 |
$5.71 |
$2.36 |
Savings from regex vs all_tools by Model
|
Model |
all_tools |
regex |
Savings |
Savings % |
|
GPT-4o-mini |
$0.28 |
$0.08 |
$0.20 |
71% |
|
GPT-4o |
$4.73 |
$1.34 |
$3.39 |
72% |
|
Claude 3.5 Sonnet |
$5.71 |
$1.64 |
$4.07 |
71% |
|
Gemini 1.5 Pro |
$2.36 |
$0.67 |
$1.69 |
72% |
Cost Projection at Scale (1M Queries)
|
Model |
all_tools |
regex |
Savings |
|
GPT-4o-mini |
$2,835 |
$803 |
$2,032 |
|
GPT-4o |
$47,300 |
$13,400 |
$33,900 |
|
Claude 3.5 Sonnet |
$57,100 |
$16,400 |
$40,700 |
|
Gemini 1.5 Pro |
$23,600 |
$6,700 |
$16,900 |
The savings scale linearly with model cost. For production deployments using Claude 3.5 Sonnet at 1 million queries, dynamic tool discovery saves approximately $40,700-making the optimization not just beneficial but essential for cost management.
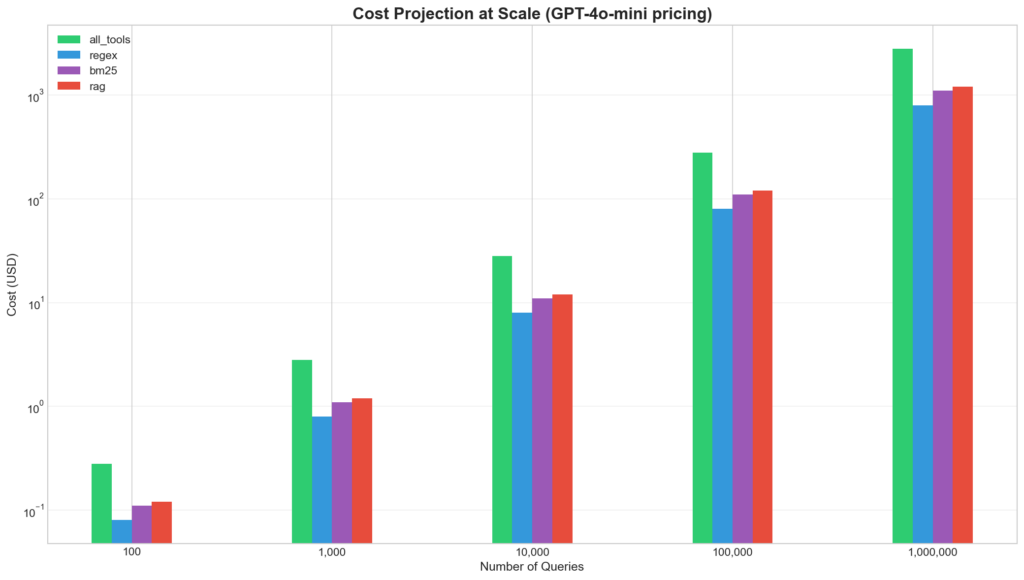
Bar chart showing cost projection at scale (100 to 1M queries).
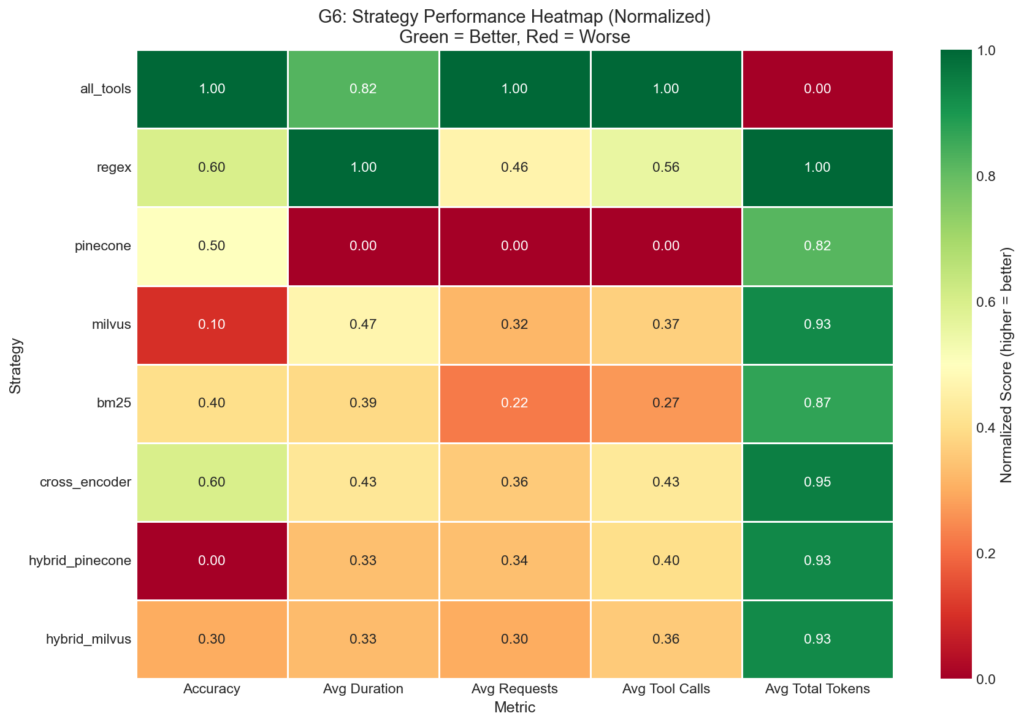
Normalized heatmap showing multi-metric performance profile.
Tool Design Guidelines
Our category accuracy analysis reveals that tool naming conventions impact retrieval accuracy more than algorithm choice. Categories with unambiguous names achieve 100% accuracy across all strategies, while ambiguous names (documents, notes, files) cause systematic failures.
Recommended naming practices:
- Use distinctive prefixes: Avoid semantic overlap between categories
- Bad:
documents_list,files_list,notes_list(confusable) - Good:
gdocs_list,dropbox_files_list,notion_notes_list(distinctive)
- Bad:
- Embed action verbs in function names:
- Bad:
get_user_info(vague) - Good:
slack_lookup_user_profile(specific)
- Bad:
- Include expected query keywords in descriptions:
def spotify_play_track(track_name: str):
"""
Play a song, music, or audio track on Spotify.
Use this for: play music, start song, listen to track, queue audio """
...- Avoid synonyms across tool boundaries:
- If
files_shareexists, don’t createdocuments_share - Consolidate or use explicit disambiguation:
files_share_linkvsdocs_grant_access
- If
When NOT to use dynamic tool search:
|
Scenario |
Recommendation |
|
< 15 tools |
Use |
|
Mission-critical accuracy |
Accept 99% baseline cost |
|
Ambiguous tool naming |
Fix naming before adding search |
|
High-stakes decisions |
Human-in-the-loop for tool selection |
Limitations & Future Work
Limitations
- Mock tools: Our 51 tools were simulations with realistic signatures but no production API integrations. Real-world tool descriptions may vary in quality and consistency.
- Single LLM: All experiments used GPT-4o-mini. Results may differ for Claude, Llama, or other models with different tool-calling behaviors.
- Fixed top-k=5: We did not optimize the retrieval depth. Larger top-k might benefit semantic methods at the cost of more tokens.
- English only: Tool names, descriptions, and queries were exclusively in English. Performance in multilingual settings is unknown.
- Binary evaluation metric: Accuracy (any expected tool called) may not capture partial success in multi-tool scenarios where 2/3 required tools were correctly invoked.
Future Work
- Adaptive retrieval: Dynamically adjust top-k based on query complexity or retrieval confidence scores.
- Query expansion: Augment user queries with synonyms or LLM-generated paraphrases before retrieval.
- Tool design study: Quantify the impact of naming conventions on retrieval accuracy. Does
send_slack_dmoutperformdm_user? What is the optimal description length? - Multi-model evaluation: Replicate experiments across Claude 3.5/4, Llama 3, Mistral, and other capable models.
- Hybrid architecture variants: Evaluate cascade, routing, and learned-weighting alternatives to RRF fusion.
- Confidence-based fallback: Detect low-confidence retrieval and automatically fall back to
all_toolsfor specific queries.
Conclusion
This study presents the first systematic comparison of retrieval strategies for tool discovery in AI agent systems. Our key findings:
- Keyword methods outperform semantic search: regex/BM25 (94% avg) > RAG/Milvus/cross-encoder (93% avg) for tool retrieval—a result that may seem counter-intuitive given the general trend toward semantic approaches in information retrieval.
- Hybrid fusion underperforms components: RRF-based hybrid (90.5%) ranked last among dynamic strategies, suggesting error amplification rather than complementary gains.
- regex achieves optimal trade-off: 95% accuracy with 73% token reduction ($0.08 vs $0.28 per 100 queries).
- Tool design matters more than search sophistication: Categories with naming ambiguity (e.g.,
documentsvsfiles) showed the largest performance gaps between strategies, highlighting that clear tool naming conventions matter more than retrieval algorithm choice.
Practical advice: Start with keyword matching. Invest engineering effort in tool naming conventions rather than sophisticated retrieval pipelines. For most production systems, regex provides the best accuracy-cost trade-off while remaining trivially simple to implement and debug.
Summirize with AI
The LLM Book
The LLM Book explores the world of Artificial Intelligence and Large Language Models, examining their capabilities, technology, and adaptation.




