RAG #7 and context window


Why RAG is not dead: a case for context engineering over massive context windows
Amid the current AI boom, you may have recently heard that RAG is dead as major AI labs compete with the capabilities of new models, offering context windows of 1M tokens and sometimes more.
If a model can process the content of several Harry Potter novels at once, why use RAG? This increasingly popular argument suggests that RAG was only necessary as a workaround for earlier models with limited context capacity. But reality is quite the opposite.
Research reveals two major arguments critics make against RAG. First, long context windows in modern large language models can now handle entire knowledge bases directly, eliminating the need for intricate retrieval systems. Second, RAG systems are overly complex, requiring the orchestration and detailed calibration of multiple components when simpler single-system solutions based on LLMs with a wide context window should suffice.
But is RAG really dead? Reality tells a different story – RAG solutions can be found in ChatGPT for storing user memories and in leading code generation tools like Cursor and Claude Code. This text will explain why the most important players in the AI market still employ some form of information retrieval tool in their most cutting-edge solutions.
What is RAG (Retrieval Augmented Generation) and what is a context window?
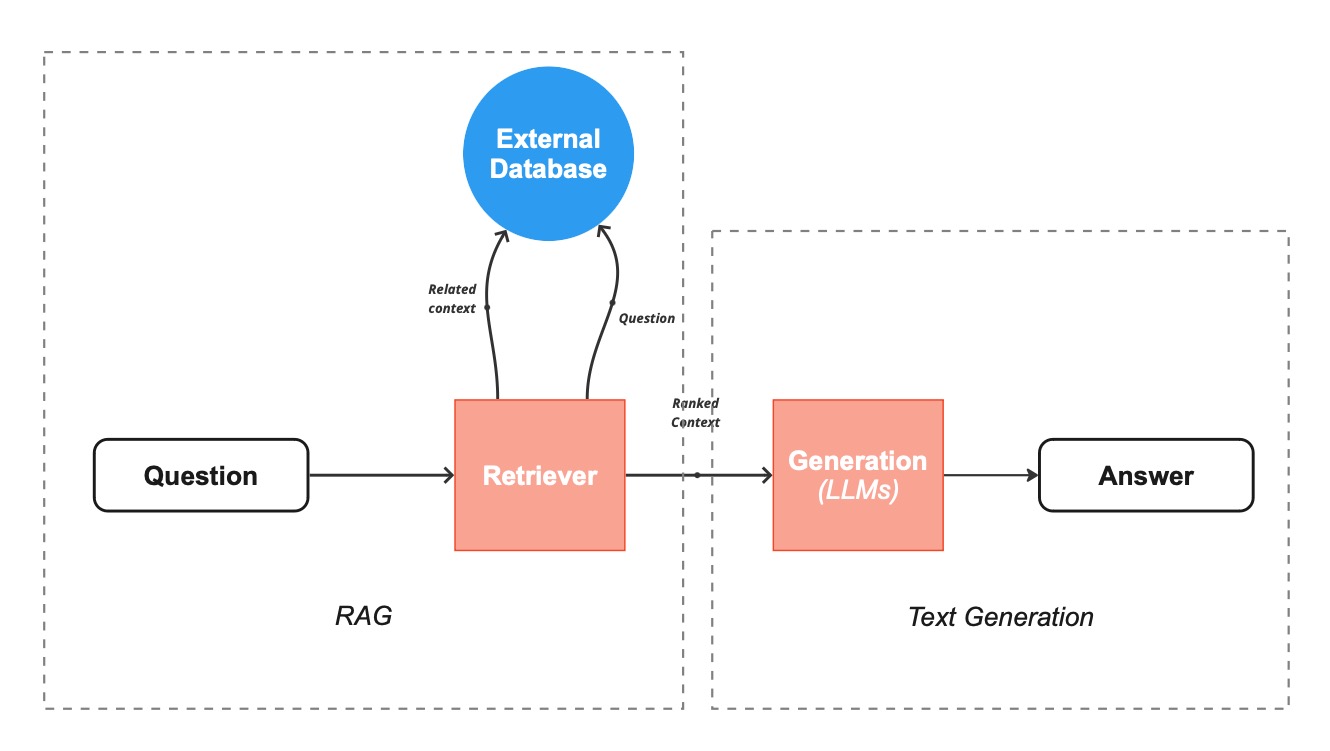
Before diving into the details, let us establish what RAG and context window actually mean. In its simplest form, RAG (Retrieval Augmented Generation) is a technique that allows an AI model to search for necessary information in external databases before providing an answer.
RAG is not just a document database. Recently, we have started talking more broadly about context engineering. This is the art of intelligently managing what information gets delivered to AI models – it includes not only document retrieval, but also context compression techniques, data organization, and the dynamic adaptation of information to specific tasks. It is like being a master of packing: instead of stuffing everything into a suitcase, you carefully select only what is really needed for the trip.
So it is about delivering our own external knowledge, that was not baked in during the training process, to the model. This includes closely guarded company databases or confidential private user information.
RAG allows LLMs to access and reference information outside the LLMs own training data, such as an organization’s specific knowledge base, before generating a response—and, crucially, with citations included. This capability enables LLMs to produce highly specific outputs without extensive fine-tuning or training, delivering some of the benefits of a custom LLM at considerably less expense.
Lareina Yee, Senior Partner of McKinsey, October 30, 2024, on What is retrieval-augmented generation (RAG)?
A context window, on the other hand, is the largest chunk of text a large language model can handle, or “keep in mind,” in any given instance. It serves as the model’s working memory, defining how much information it can use when generating a response. To greatly simplify, think of a context window as a chat interface, like GPT: everything you input into the model plus what the model returns counts toward the context window (there are also tokens we do not see, like a set of system instructions). One of the major arguments is to simply leverage this capacity by loading all available information directly into the context window without any pre-filtering or selection.
The use of a RAG pattern or its neglect represent fundamentally different philosophies for information access: the difference is similar to that of a smart assistant who knows where to look for answers to specific questions (RAG), and an overzealous one brings along all possible documents “just in case” (large context window). The second option feels reassuring, but is impractical in daily use.

Context rot: the pitfall of larger context windows in LLM performance
Expanding context windows has indeed been impressive in recent years. GPT’s context window has exploded from a modest 2,048 tokens in GPT-3 to a full 1,000,000 tokens in GPT-4.1; as Gemini, through its Flash, Pro variants, has consistently led proprietary models with best-in-class million-token capacities; while Qwen2.5-14B-Instruct-1M was the first open-source LLM to reach the 1M-token mark.
| Release Date | Model Name | Context Window |
|————–|————|—————-|
| 2020/06 | GPT-3 | 2,048 tokens |
| 2022/11 | GPT-3.5 | 4,096 tokens |
| 2023/03 | GPT-4 | 8,192 tokens |
| 2023/03 | GPT-4-32k | 32,768 tokens |
| 2024/05 | GPT-4o | 128,000 tokens |
| 2024/12 | o1 | 200,000 tokens |
| 2025/04 | GPT-4.1 | 1,000,000 tokens |
To put this in perspective, imagine if your AI assistant went from being able to read a short blog post to suddenly processing entire novels, research papers, or even small document databases all at once. A million tokens is roughly equivalent to 750,000 words – that’s about 200 typical academic research papers.
However, larger context windows do not automatically translate to equally long outputs, as maximum generation length remains separately capped by model-specific decoding limits. It is like a translator who can read and understand an entire foreign novel from cover to cover, keeping every detail in mind, but when translating it back, they are limited to producing just one chapter at a time.
But here is another catch: just because these models can technically handle a million tokens does not mean they do it well. It is akin to asking someone to remember every detail of a 500-page book they just read—sure, they finished it, but can they really recall what happened on page 237? The same goes for AI models. They often “forget” important information buried in the middle of long texts, focusing mainly on what they read at the beginning and end. Plus, processing such massive amounts of text gets expensive fast, sometimes costing 100 times more than processing a standard query, and takes much longer too.
So what is the bottom line? While these massive context windows sound revolutionary, they come with serious trade-offs. The “lost in the middle” problem gets worse with longer texts. Models optimized for ultra-long contexts often stumble on regular tasks, becoming so specialized for extreme lengths that they have lost everyday agility. Even advanced models show cracks as context grows, with attention wandering and accuracy dropping. The technology is impressive, but we are still far from models that can truly “read” and comprehend a million tokens like they can handle a simple paragraph.
Building better AI: transparency and explainability
One of the most important factors hindering broader AI adoption in companies is the quality and reliability of data produced by models. Nothing undermines the credibility of agentic systems or the companies deploying them more than erroneous, hallucinated answers.
Even if we send reliable organizational data to the model’s context, and even if the model actually manages to extract information, this is not always sufficient. Users expect transparency and reliability, especially in critical areas related to law or medicine.

Language models with large contexts most often operate as black boxes, meaning they cannot reliably provide sources for generated answers.
RAG systems, on the other hand, can show where information comes from and how answers are created, which is important for companies with strict rules. For example, when a legal assistant powered by RAG answers, “The statute of limitations for this case is 3 years,” it can immediately show you it pulled this from Section 2.3 of the Civil Code, last updated on May 5, 2022, with a confidence score of 97%. A regular large-context model might give the same answer but cannot reliably tell you whether it came from page 5 or page 500 of the document you uploaded—or worse, if it is mixing information from different sources.
While LLM weights are difficult to inspect, RAG provides transparency into its information sources and can rate how reliable the returned data is. This openness helps companies follow regulations as these systems keep detailed records that regulators want to see, so companies can prove how they made decisions and what sources they used. This is crucial in industries with strict controls where AI choices must be backed up with evidence and easy to verify.
Performance and cost
There is another practical argument against expanding context windows. And it is surprising that it is so rarely raised in discussion, considering it remains a priority for every CEO investing in AI applications – processing large numbers of tokens is simply slow and expensive. While every creator of agentic applications works hard to make their system run quickly without generating excessive token-related costs.
Imagine you are building an agent to help drivers find relevant information in user manuals for different car models. Modern cars are packed with electronics. When a desperate owner of a new vehicle tries to figure out how to quickly activate the heated seats in freezing weather, you can solve this problem in several ways.
While RAG implementation requires upfront investment in indexing systems and retrieval infrastructure, wide context window processing can work ad hoc by simply loading entire documents into the model’s context.
So one option would be to dump the hefty instruction manual in PDF format or the entire contents of the manual database into a language model with a wide context window, asking it to find the appropriate section for seat heating instructions. This represents the approach of the RAG Is Dead theory supporters.
Would this solution work? Most likely yes, maybe the user would not even freeze while waiting for relevant results. Maybe the open LLM would even provide instructions for the car the driver is actually in.
However, a more reliable (and possibly cheaper long term) solution would be in using a RAG process which already has indexed manuals. In the first step, it quickly narrows the search area to heating-related topics, then passes several selected manual fragments to the language model. The model will return the desired information, providing precise source information, including the specific car model.
The process of reducing context, and thus latency and cost, is a natural stage in developing any agentic application. Initially during the proof of concept stage, we check if the general project idea is feasible, not worrying about costs. We can therefore choose the best and not necessarily the cheapest available model, providing it with many examples. Remember the assistant who hoards all documents just in case?
However, in subsequent iterations toward launching the production version, we consider how to use smaller and faster models. So less, but better selected context, while maintaining accuracy. Various context retrieval strategies are indispensable in this process.
Summary: Agentic RAG models vs context length
This is just one example. In practice, every application creator strives to limit, not expand, the context of processed information, because this guarantees lower latency, greater accuracy and reduced service costs. Even if wide model context is available, it is still worth investing in context engineering – selective delivery of the most appropriate content to the model.
RAG is not disappearing, but is being replaced by more sophisticated agentic systems that combine LLM-based agents with various data sources. Instead of by default burying the agent’s context with mostly irrelevant data, system creators strive to provide the agent with a series of filtered and precise information from multiple sources. This approach maintains balance between performance and cost as well as precision and accountability based on company-specific data. It appears to be the key to success in AI implementations.
To ensure reliability and accuracy, these agent-based systems use continuous monitoring and bias reduction techniques. They incorporate structured outputs and tool responses to improve their capabilities, while maintaining chat history and contextual awareness to make better decisions across multiple interactions. Future development of these AI agents focuses on handling complex queries, improving retrieval methods, and refining indexing techniques to create adaptive architectures that meet security and compliance requirements while working across different data environments.
The LLM Book
The LLM Book explores the world of Artificial Intelligence and Large Language Models, examining their capabilities, technology, and adaptation.