Adding Monty: a lightweight sandbox for model-written Python


Most agentic systems eventually need to run code the model wrote. The real question is not whether to allow it, but how much machine to spin up each time. We added Monty to the Full-Stack AI Agent Template to answer that at the cheap end of the range: a snippet of Python that has to run once, return a value, and disappear, without a container behind it.
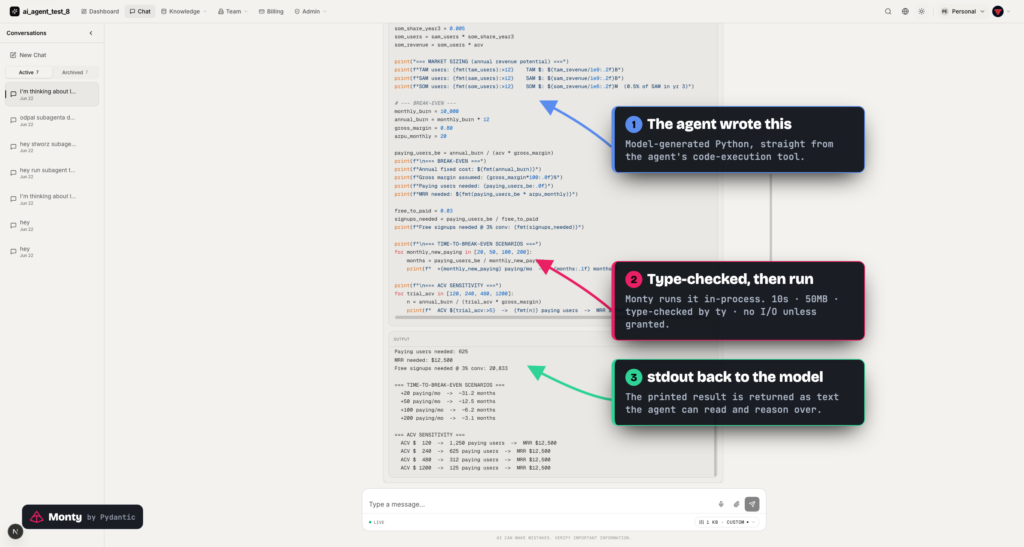
We added Monty as the sandbox for executing model-written Python in the Full-Stack AI Agent Template. Monty is a minimal, secure Python interpreter written in Rust by Pydantic, built to run LLM-generated code with microsecond start-up and no I/O which it was not explicitly handed.
This is short, because the interesting part is not Monty on its own. It is where it fits. The template now has three ways to run code, and they do different jobs.
Three ways to run code
For agents that need a real environment (a shell, a filesystem, pip install), the template already ships two sandbox backends: a Docker backend and a Daytona backend. Both give you full isolation. Both cost a real cold start and some infrastructure per run. That is the right trade when the agent has to build and run an actual project.
Running a snippet the model wrote is a different case. There, the model writes a small piece of Python, computes an aggregation or a projection, and returns a result. Spinning a container for that is too heavy, and a remote Daytona sandbox is more than you need.
That is the tier Monty fills.
|
| Docker / Daytona backend | Monty |
| Use case | full agent environment (shell, files, pip) | a tool that runs a snippet of code |
| Startup per call | hundreds of ms (cold start) | microseconds, in-process |
| Isolation model | container / remote sandbox | allow-list: no I/O unless passed in |
| Type-check before run | no | yes (Astral |
| Full Python / stdlib | yes | no, a subset |
What Monty gives you
The core idea is that Monty has no I/O by default. Filesystem, network, environment variables: each one is an external function you pass in. The code the model writes can reach exactly the functions you registered and nothing else. You choose the whole surface up front, rather than maintaining a deny-list and hoping you did not miss a builtin.
On top of that, startup is in microseconds rather than the hundreds of milliseconds a container costs, and the ty type checker from Astral is compiled in, so model-written code can be type-checked before it runs.
How it is wired
In the template, the code-execution tool is a normal Pydantic AI tool. The model’s code goes straight to Monty under a resource leash:
from pydantic_monty import CollectString, Monty, MontyError, ResourceLimits
collector = CollectString()
limits = ResourceLimits(
max_allocations=settings.CODE_EXECUTION_MAX_ALLOCATIONS, # 50_000_000
)
try:
monty = await Monty.acreate(code) # code = Python the model just wrote
output = await monty.run_async(print_callback=collector, limits=limits)
except MontyError as e:
return f"Execution failed: {e}"The allowed stdlib is trimmed to json, datetime, re and asyncio (Monty exposes only a small subset of the standard library, so math and friends are not available). There is a 10 second timeout and a 50M allocation cap. The tool returns the captured stdout plus the value of the final expression, or an error string the model can read and recover from. It is opt-in: generate with --code-execution (PydanticAI only) and set ENABLE_CODE_EXECUTION=true at runtime.
Where this is going
Monty is early. We pin pydantic-monty>=0.0.18, and at this stage it does not support class definitions, match statements, context managers or generators, and most of the standard library is absent. For the “compute this, return that” code an LLM writes in a tool call, that has been enough. We treat the integration as a shim: when Pydantic AI’s official CodeExecutionToolset ships, the template swaps to it.
The rule of thumb stays the same either way. Use the Docker or Daytona backend when the agent needs an environment. Use Monty when a tool just needs to run code.
But the wider point is about best fit. A template is more useful when it gives you graded options than when it forces one heavy-ended default. Three execution tiers mean the cost of running code now matches the size of the job, from a full sandboxed environment down to a single in-process snippet. Monty is the small end of that range, and for the code an LLM writes in a tool call, the small end is often all you need.
Browse the template (MIT): github.com/vstorm-co/full-stack-ai-agent-template. Or build your stack in the browser with the web configurator.
More on Monty: the pydantic/monty repo and Pydantic’s Monty article.
Build your own agent stack
The Full-Stack AI Agent Template is open source under the MIT licence. Clone it, generate with --code-execution, and you have Monty wired in as the lightweight execution tier from the first run. Prefer to start in the browser? The web configurator lets you assemble your stack and export it without touching the command line.
Browse the template: github.com/vstorm-co/full-stack-ai-agent-template
If you would rather talk through how this fits your own agentic systems, meet directly with our founders and PhD AI engineers.
Summarize with AI
The LLM Book
The LLM Book explores the world of Artificial Intelligence and Large Language Models, examining their capabilities, technology, and adaptation.




